State-of-the-art medical multi-modal LLMs (med-MLLMs), such as LLaVA-Med and BioMedGPT, primarily depend on scaling model size and data volume, with training driven largely by autoregressive objectives. However, we reveal that this approach can lead to weak vision-language alignment, making these models overly dependent on costly instruction-following data. To address this, we introduce ExGra-Med, a novel multi-graph alignment framework that jointly aligns images, instruction responses, and extended captions in the latent space, advancing semantic grounding and cross-modal coherence. To scale to large LLMs (e.g., LLaMa-7B), we develop an efficient end-to-end training scheme using black-box gradient estimation, enabling fast and scalable optimization. Empirically, ExGra-Med matches LLaVA-Med's performance using just 10% of pre-training data, achieving a 20.13% gain on VQA-RAD and approaching full-data performance. It also outperforms strong baselines like BioMedGPT and RadFM on visual chatbot and zero-shot classification tasks, demonstrating its promise for efficient, high-quality vision-language integration in medical AI.
✅ Reveals the data inefficiency of autoregressive modeling — LLaVA-Med exhibits a significant performance drop when pre-trained on limited data, even after full fine-tuning on downstream tasks.
✅ Matches LLaVA-Med's performance on Medical VQA using only 10% of the pre-training data, demonstrating the data efficiency of EXGRA-MED.
✅ Surpasses several SOTA medical multi-modal LLMs when pre-trained on the full PMC-15M
dataset (100%) with LLaMA-7B, across diverse tasks:
1. Medical Visual Question Answering (VQA)
2. Medical Visual Chatbot
3. Zero-shot Image Classification (as a VQA task)
 Overview of EXGRA-MED
Overview of EXGRA-MED
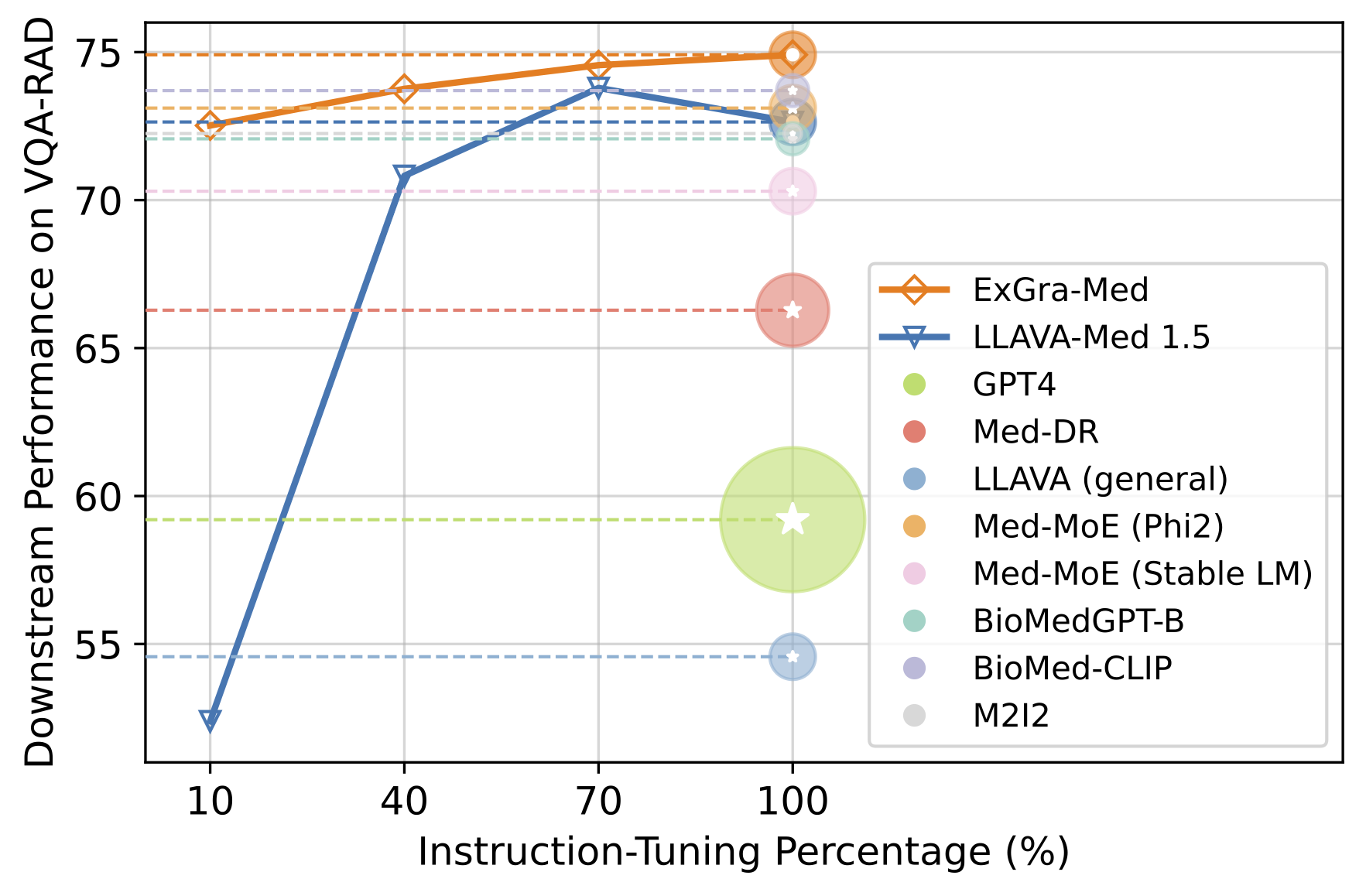
Results
@article{nguyen2025exgra,
title={EXGRA-MED: Extended Context Graph Alignment for Medical Vision- Language Models},
author={Duy M. H. Nguyen, Nghiem T. Diep, Trung Q. Nguyen, Hoang-Bao Le, Tai Nguyen, Tien Nguyen, TrungTin Nguyen, Nhat Ho, Pengtao Xie, Roger Wattenhofer, James Zou, Daniel Sonntag, Mathias Niepert},
journal={arXiv preprint arXiv:2410.02615},
year={2025}
}